Writing, photos and videos added July 31, 2026
Stable product development and the investment in data centers for a sustainable digital future.
Recent work
In 2026, tech is investing in data centers across the U.S. to support AI in this century. For product managers and designers in identity tech, the next 25 years are critical for stable product development.
Recently, Microsoft and DataOne, which also has a partnership with Nvidia, invested in the town where I was born and the in-development data center highlights the tension between a sustainable environment and a sustainable digital future.
I previously led a big tech content design team responsible for location, age, gender and ad targeting products. Working in highly-regulated industries like tech and financial services, I’ve also led procedure for data retention and legal review processes.
I’ll be online at the University of Washington’s Information Science graduate program starting Autumn 2026, where I’ll be exploring how we understand people and our national identity as digital data. I can live anywhere in the world, so if you know of any sustainable tech organizations looking for a senior manager or IC in product management or design, let me know.
I’ve been missing living and working in the U.K., especially London!
Writing, design and ideas by Brittney Michele Dunkins unless cited.
U.S. Fulbright to Taiwan 2026-27
I applied to the U.S. Fulbright program to Taiwan last term to study AI in the U.S. Taiwan and China. I didn’t get the grant, but hoping to apply again in the future and visit Taiwan and China. I may write more about China’s AI tigers.
Recent work
Recording the national identity: A fully digital future public
The state of AI in the U.S., Taiwan and China: During the fall of 2020, the Fulbright U.S. Student Program to Mainland China ended, a move during the final few months of the first Trump presidential administration. I relocated to the UK the day after election day, for a position with Meta London. I spent the next three years as an American in the U.K. leading a team responsible for Meta’s ads products—the five-year-old Ad Targeting product being the core responsibility as it transitioned to automation.
Automation language quickly evolved to AI between 2023 and 2025, and companies like Nvidia have been in the spotlight. Nvidia, which develops advanced AI chips, is based in Santa Clara, Calif. along with Intel. Both Nvidia and Intel have a presence in China— the former in Beijing and the latter in Chengdu.
TSMC is a Taiwanese company with a presence in Shanghai. Second to the tech-focused Beijing, Shanghai is the more traditional city for business. Nvidia partnered with TSMC to produce AI chips, and recent reports highlight changing government relations among Taiwan, the U.S. and China.
Following the first 100 days of the second Trump administration, the U.S. announced tariffs on China and Japan at the same time during spring 2025, and a truce was announced allowing Nvidia to purchase chips from TSMC during the summer—the truce was extended and Nvidia CEO Jensen Huang was well-received in China.
Nonprofit OpenAI (now a public company) has also partnered with Nvidia. AI chip development and exports to the U.S. and countries globally have made Taiwan foundational to the future of AI.
Recording an evolving national identity: The purpose of my project is to create an interactive experience about the evolving national identity of Taiwan, the U.S. and China. My research will focus on the relationship between “Big Tech” and government, AI and identity data.
The research will contribute to documenting AI in the U.S., Taiwan and China and how all three countries may be moving toward a fully digital future public. As an American in Taiwan, my interest is specific to how the host country may contribute to this evolution.
A fully digital future public in the United States is likely in this century, and by 2050 a global cloud could store both the national identity and the identity data of countries around the world.
The responsibility of people and government: The research is work into our data future. My study focuses on shaping the responsibility of people and government and the design of how we understand the national identity as digital data.
Investment in data centers, a positive relationship between AI tech and the new presidential administration, an upcoming 2030 U.S. census and the release of Login.gov are a move toward a future public understood as digital data.
During my stay in the host country, I plan to record interviews with tech employees, university students and researchers in Taiwan, China and the U.S. My research will also aim to include observations at TSMC and National Tsing Hua University in Hsinchu, and if possible—TSMC, Tsinghua University and Nvidia in Beijing. The flight from Taiwan to China is a little more than three hours.
Writing, design and ideas by Brittney Michele Dunkins unless cited.
Writing, photos and video added Feb. 12, 2025
Data, storage, devices and computing power
The stability of memory of data/countries in the 21st century
Recent work
While standing in an apartment you can’t find on Google Maps, I pinch to search on my mobile phone for the Clonshaugh data center and listen to “Power Grab: the hidden cost of Ireland’s datacentre boom,” reported and written by Jessica Traynor for The Guardian’s Audio Long Read.
The story details “the long and patchy memory” of Ireland, the country’s rise as the “Celtic Tiger,” and a possible future of instability.
Data
Traynor’s anxiety about the country is an eerie contrast to her description of acquiescing to the task of managing her data. She describes spending a few hours of moving her family files to cloud storage after receiving a common notification: your storage is almost full.
Writing, photos and video added Oct. 19, 2024

Her experience with data in Ireland is a parallel to the U.S. I’ve experienced since returning to America last spring.
After 35 years as an American citizen and working internationally for a major tech company from 2020 to 2023, I began to see my life as data. Messages, emails, images, accounts, passwords, mobile numbers and apps stored across devices. The complexity of life as a global professional is managing an identity understood as logins.
Data and identity
The top left of my U.K. mobile phone reads SOS and by June 2023, access to my U.S. mobile phone isn’t available. My United States passport is scanned during visits to AT&T and I’m told that a passcode or pin is required to access my account from the store. I spend a long afternoon on a landline waiting to be transferred to customer service.
The line goes dead.

Alt text: The commute from the Greater Anglia train, Suffolk to London. Railroad tracks, fields, trees and a cloudy bright sky.
During a visit to the Apple store during the Spring of 2023, I’m told that my two Apple IDs—one created in 2020 with my U.K. Gmail, U.K. mobile number, and U.K. address—and one created around 2008 with my U.S. Gmail, U.S. mobile number and U.S. address— aren’t allowed under Apple’s policies.
My mobile phones and two Apple accounts are linked to my personal and professional devices, some issued by former employers.
I’m unsure if having two separate devices, as a U.S. citizen living and working in the U.K., is a typical use case, but the rationale was to organize the complexity of my identity documented by major institutions including governments, banks, and employers.
Alt text: The Deben river from a grass and dirt path; houses and trees in the far distance below a cloudy bright sky.
Writing, photos and video added Oct. 19, 2024
The contrast to the tension in the U.S. during the years after 2020 makes it seems as though I was living a life of leisure.
When the UK opened for an extended period in 2021, I walked along the Deben midday, a break from my desk on the upper floor of the flat, adjoined to another flat. The village, a market town, was quiet for the first year or so, and long after masks were mandated, everyone continued wearing their masks for the older and retired. At the pharmacy, I considered the stories of people in the U.S. arguing about having to wear a mask.
It’s an oddly frustrating thing to consider, but you can be born in a country where your family has lived for generations, never have been unemployed, graduate with an undergraduate and graduate degree, have no criminal history and have your citizenship disregarded.
Writing, design and ideas by Brittney Michele Dunkins unless cited.

Caption: Brittney Michele Dunkins in Philadelphia. Recently, I’ve been working on a few ideas about period tech, data storage, AI hardware devices, and the limits of financial services when managing a global life. I’ve been editing audio and video, writing and interviewing and updating my portfolio. There’s a design file I haven’t opened this week.
Alt text: A woman stands in front of a bicycle, a truck and a bus near Rittenhouse Square.
Recent work
Reading an MIT Technology Review article about large language models (LLM) from a coffee shop, today. About a year ago, I was sharing ChatGPT with a team of content designers I managed in a weekly meeting. We all challenged the model to express tonal nuance in funny ways: “Write a passive aggressive roommate agreement for my puppy.” The exact language is stored somewhere, I’m sure.
Audio added April 5, 2024.
Caption: Working on an article about large langauge models at a coffeeshop. Alt text: A woman typing on a laptop in the late morning.
News and academic writing about AI, and generative AI, have been published quickly in the last year. And while the tech may seem completely new, SXSW quotes about “tech super cycles” and my short-lived experiment migrating to new products like Microsoft Edge, are a repeat of conversations about how to explain machine learning.
I’m not an expert, but writing an explanation of new or changing tech for myself is often a way to design and write explanations people can understand. Below are a few notes, questions and terms. Send your feedback, explanations or questions; I’d love to know how designers are thinking about and understanding AI.

A table describing the cumulative proficiency of humans in parallel to large language models, AI.
Terms to explore
large language model
data*
parameter
training
training data
overfit
underfit
generalization
token
prompt
neural network architecture
statistical language model
device
computing device
hardware device
language model
model
*limited definition
Updated April 4, 2024
Notes on training large language models
Large language models are trained with data to perform simple and complex functions. The article characterizes engineers as teachers that provide a function to be completed by connecting data to a model.
Training a model, with reference to OpenAI’s research, describes a model’s learning as a similar process to training any worker. AI in this article is characterized as learning to complete a task or job through training, rather than completing a complex function after an extensive education. For example: learning to write a recipe or learning and then creating a unique recipe with parameters, such as the omission of certain ingredients or a balance of flavors (sweet, salt, sour, bitter and umami).
A parallel to training large language models can be made to the commonly understood hierarchy of education, and, for most people, the required knowledge, skills, analysis—and at the highest level— the ability to produce a unique understanding, idea, object and action.
My questions
Is an engineer a parameter for model training?
What patterns can a large language model find?
Term explorations about AI are required to understand, challenge and in some cases eliminate the definitions provided by companies that don’t share mutual business perspectives or objectives. While the terms here may seem introductory, the approach is defined as similar to media literacy— the comparison of media, information, to form a comprehensive view or understanding of a term in and out of context.
Writing, design and ideas by Brittney Michele Dunkins unless cited.
Writing, terms, chart and video added March 22, 2024
Concept map : Large language model data
Concept mapping is a content design method to analyze language before developing terms and definitions. I first used this method as a content designer at Meta Platforms, Inc., Facebook UK, Ltd., located in London where I was trained to be a terminology reviewer and later, a term lead. I’ll likely write more about concept mapping in a later post.
In an earlier post, I identified common terms that require standard definitions. The map clarifies the relationship between two identified terms: large language model and data.
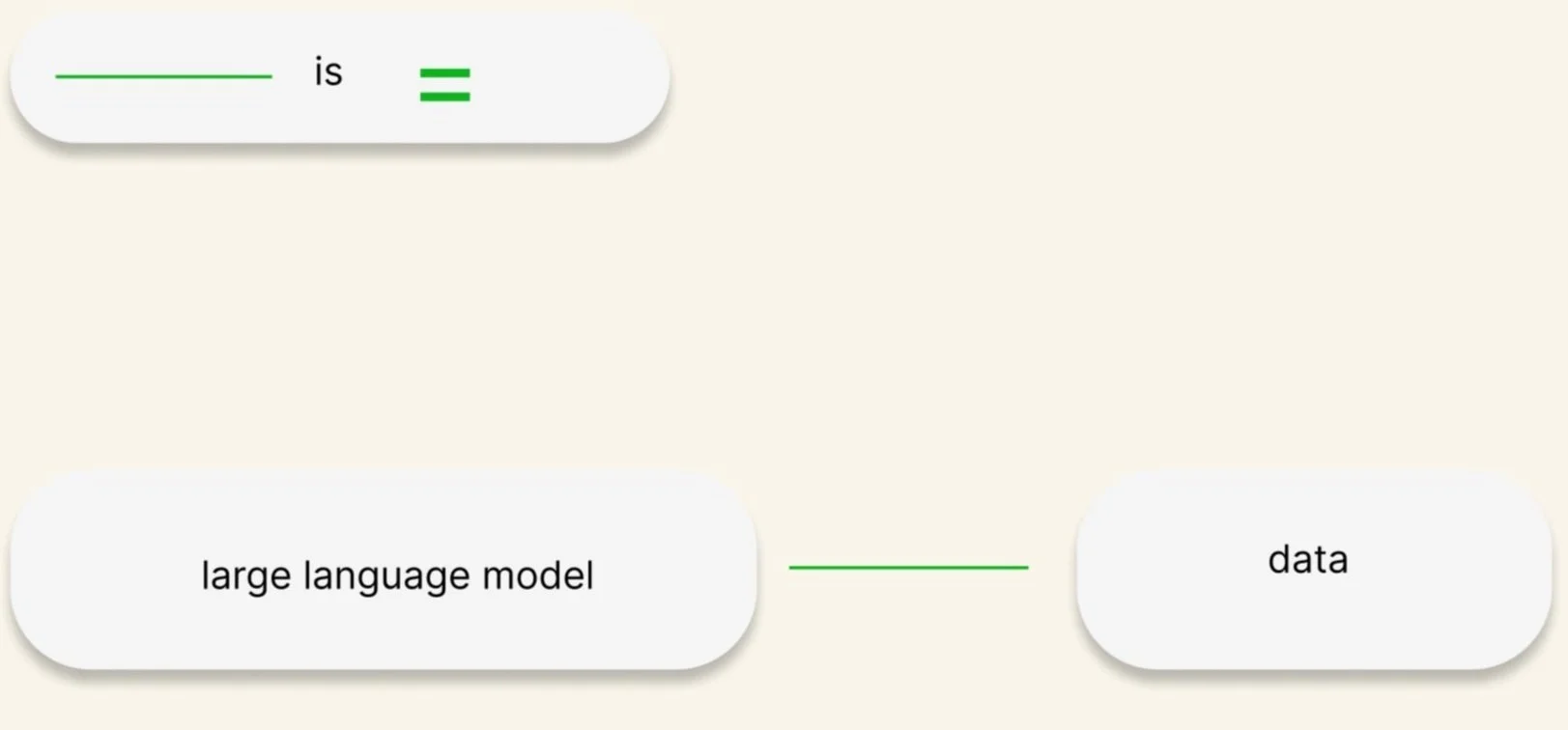
A large language model (LLM) is data. Data is a word that the AI industry uses in the context of teaching or training an LLM. The concept map below includes the three types of data of an LLM, publicly available, licensed, and a word or sentence provided by a human or a graphics processing unit (GPU). See source material below.
The types can be understood as distinct limits. I’ll continue exploring the third type of data, or the language used to describe a token, prompt, neural network architecture, a statistical language model, and a device, including a computing device or a hardware device.
A note that the colors chosen for this post, HEX #F4F5E, #10B320, #6EB5FC, and #000000, are a reference to the colors used in the source material. Concept maps designed using Figma.

Concept map: Large language model data
Concept maps developed April 3, 2024 with reference to the language used by OpenAI, the Microsoft Corporation, Google LLC, the Mozilla Corporation, Nvidia Corporation and Inflection AI, Inc.
Sources
I read the sources below and recommend them if you’re interested in language describing large language models (LLM) and AI.
If you have any sources to share, you can send an email using the Request CV button.
https://help.openai.com/en/articles/8868588-retrieval-augmented-generation-rag-and-semantic-search-for-gpts
https://help.openai.com/en/articles/8983117-how-does-openai-use-my-personal-data
https://help.openai.com/en/articles/7842364-how-chatgpt-and-our-language-models-are-developed
https://learn.microsoft.com/en-us/training/modules/introduction-large-language-models/2-understand-large-language-models
https://learn.microsoft.com/en-us/training/modules/introduction-large-language-models/2-understand-large-language-models
https://cloud.google.com/ai/llms
https://ai-guide.future.mozilla.org/content/llms-101/
https://www.merriam-webster.com/dictionary/GPU
https://www.oxfordlearnersdictionaries.com/us/definition/english/gpu
https://inflection.ai/inflection-1
https://www.nvidia.com/en-us/technologies/multi-instance-gpu/
Caption: Brittney Michele Dunkins in Philadelphia. Recently, I’ve been working on a few ideas about period tech, data storage, AI hardware devices, and the limits of financial services when managing a global life. I’ve been editing audio and video, writing and interviewing and updating my portfolio. There’s a design file I haven’t opened this week.
Alt text: A woman stands in front of a bicycle, a truck and a bus near Rittenhouse Square.
Recent work
Reading an MIT Technology Review article about large language models (LLM) from a coffee shop, today. About a year ago, I was sharing ChatGPT with a team of content designers I managed in a weekly meeting. We all challenged the model to express tonal nuance in funny ways: “Write a passive aggressive roommate agreement for my puppy.” The exact language is stored somewhere, I’m sure.
Audio added April 5, 2024.
Caption: Working on an article about large langauge models at a coffeeshop. Alt text: A woman typing on a laptop in the late morning.
News and academic writing about AI, and generative AI, have been published quickly in the last year. And while the tech may seem completely new, SXSW quotes about “tech super cycles” and my short-lived experiment migrating to new products like Microsoft Edge, are a repeat of conversations about how to explain machine learning.
I’m not an expert, but writing an explanation of new or changing tech for myself is often a way to design and write explanations people can understand. Below are a few notes, questions and terms. Send your feedback, explanations or questions; I’d love to know how designers are thinking about and understanding AI.
A table describing the cumulative proficiency of humans in parallel to large language models, AI.
Terms to explore
large language model
data*
parameter
training
training data
overfit
underfit
generalization
token
prompt
neural network architecture
statistical language model
device
computing device
hardware device
language model
model
*limited definition
Updated April 4, 2024
Notes on training large language models
Large language models are trained with data to perform simple and complex functions. The article characterizes engineers as teachers that provide a function to be completed by connecting data to a model.
Training a model, with reference to OpenAI’s research, describes a model’s learning as a similar process to training any worker. AI in this article is characterized as learning to complete a task or job through training, rather than completing a complex function after an extensive education. For example: learning to write a recipe or learning and then creating a unique recipe with parameters, such as the omission of certain ingredients or a balance of flavors (sweet, salt, sour, bitter and umami).
A parallel to training large language models can be made to the commonly understood hierarchy of education, and, for most people, the required knowledge, skills, analysis—and at the highest level— the ability to produce a unique understanding, idea, object and action.
My questions
Is an engineer a parameter for model training?
What patterns can a large language model find?
Term explorations about AI are required to understand, challenge and in some cases eliminate the definitions provided by companies that don’t share mutual business perspectives or objectives. While the terms here may seem introductory, the approach is defined as similar to media literacy— the comparison of media, information, to form a comprehensive view or understanding of a term in and out of context.
Writing, design and ideas by Brittney Michele Dunkins unless cited.
Writing, terms, chart and video added March 22, 2024
Concept map : Large language model data
Concept mapping is a content design method to analyze language before developing terms and definitions. I first used this method as a content designer at Meta Platforms, Inc., Facebook UK, Ltd., located in London where I was trained to be a terminology reviewer and later, a term lead. I’ll likely write more about concept mapping in a later post.
In an earlier post, I identified common terms that require standard definitions. The map clarifies the relationship between two identified terms: large language model and data.
A large language model (LLM) is data. Data is a word that the AI industry uses in the context of teaching or training an LLM. The concept map below includes the three types of data of an LLM, publicly available, licensed, and a word or sentence provided by a human or a graphics processing unit (GPU). See source material below.
The types can be understood as distinct limits. I’ll continue exploring the third type of data, or the language used to describe a token, prompt, neural network architecture, a statistical language model, and a device, including a computing device or a hardware device.
A note that the colors chosen for this post, HEX #F4F5E, #10B320, #6EB5FC, and #000000, are a reference to the colors used in the source material. Concept maps designed using Figma.
Concept map: Large language model data
Concept maps developed April 3, 2024 with reference to the language used by OpenAI, the Microsoft Corporation, Google LLC, the Mozilla Corporation, Nvidia Corporation and Inflection AI, Inc.
Sources
I read the sources below and recommend them if you’re interested in language describing large language models (LLM) and AI.
If you have any sources to share, you can send an email using the Request CV button.
https://help.openai.com/en/articles/8868588-retrieval-augmented-generation-rag-and-semantic-search-for-gpts
https://help.openai.com/en/articles/8983117-how-does-openai-use-my-personal-data
https://help.openai.com/en/articles/7842364-how-chatgpt-and-our-language-models-are-developed
https://learn.microsoft.com/en-us/training/modules/introduction-large-language-models/2-understand-large-language-models
https://learn.microsoft.com/en-us/training/modules/introduction-large-language-models/2-understand-large-language-models
https://cloud.google.com/ai/llms
https://ai-guide.future.mozilla.org/content/llms-101/
https://www.merriam-webster.com/dictionary/GPU
https://www.oxfordlearnersdictionaries.com/us/definition/english/gpu
https://inflection.ai/inflection-1
https://www.nvidia.com/en-us/technologies/multi-instance-gpu/
Writing, design and ideas by Brittney Michele Dunkins unless cited.
Writing and concept maps added April 3, 2024